MODULE assim_tools_mod
Overview
This module provides subroutines that implement the parallel versions of the sequential scalar filter algorithms. These include the standard sequential filter as described in Anderson 2001, 2003 along with systematic correction algorithms for both mean and spread. In addition, algorithms to do a variety of flavors of filters including the EAKF, ENKF, particle filter, and kernel filters are included. The parallel implementation that allows each observation to update all state variables that are close to it at the same time is described in Anderson and Collins, 2007.
Localization
Localization controls how far the impact of an observation extends. The namelist items related to localization are spread over several different individual namelists, so we have made a single collected description of them here along with some guidance on setting the values.
This discussion centers on the mechanics of how you control localization in DART with the namelist items, and a little bit about pragmatic approaches to picking the values. There is no discussion about the theory behind localization - contact Jeff Anderson for more details. Additionally, the discussion here applies specifically to models using the 3d-sphere location module. The same process takes place in 1d models but the details of the location module namelist is different.
The following namelist items related to 3d-sphere localization are all found in the input.nml file:
&assim_tools_nml :: cutoffvalid values: 0.0 to infinity
This is the value, in radians, of the half-width of the localization radius (this follows the terminology of an early paper on localization). For each observation, a state vector item increment is computed based on the covariance values. Then a multiplier, based on the ‘select_localization’ setting (see below) decreases the increment as the distance between the obs and the state vector item increases. In all cases if the distance exceeds 2*cutoff, the increment is 0.
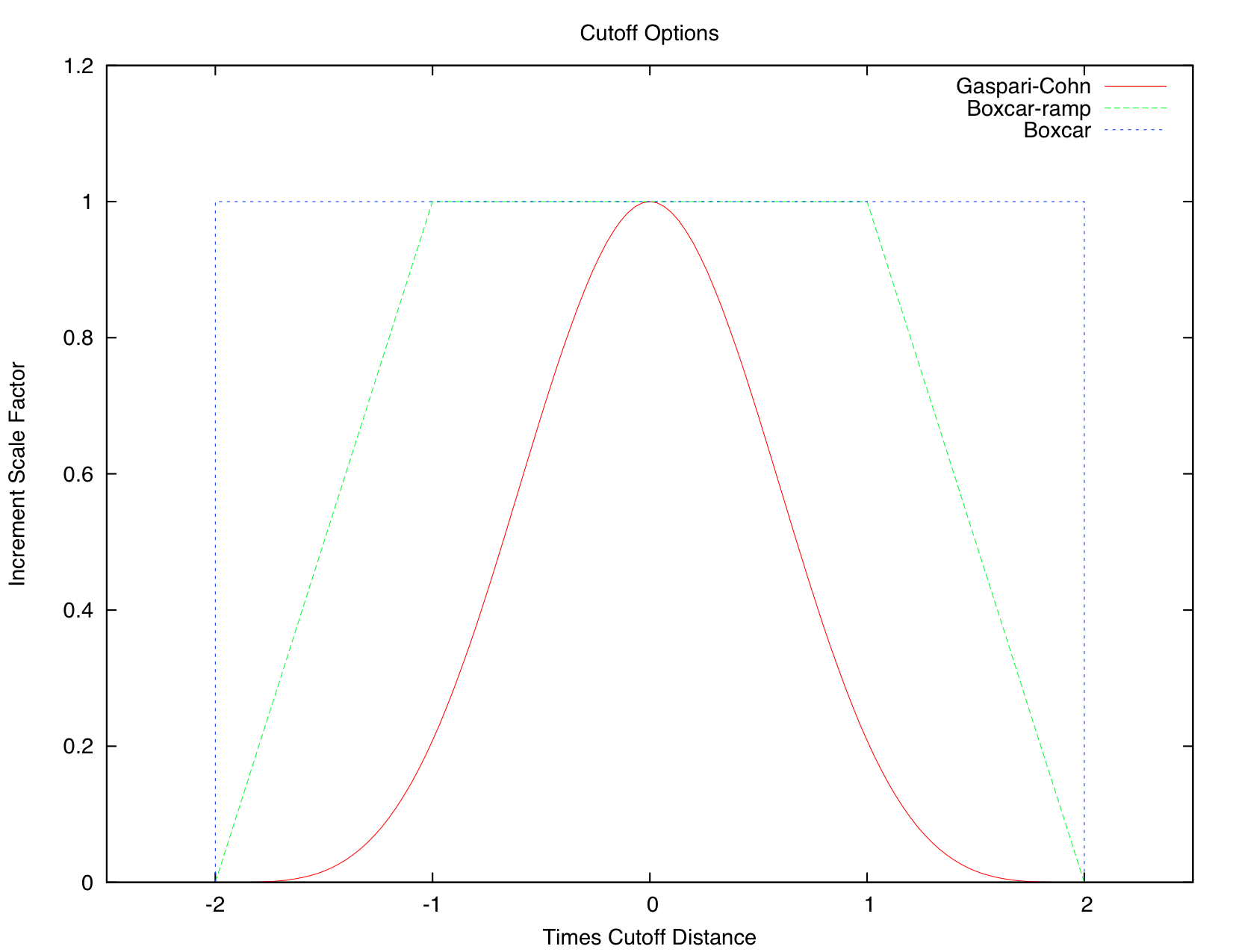
&cov_cutoff_nml :: select_localizationvalid values: 1=Gaspari-Cohn; 2=Boxcar; 3=Ramped Boxcar
Controls the shape of the multiplier function applied to the computed increment as the distance increases between the obs and the state vector item. Most users use type 1 localization.
Type 1 (Gaspari-Cohn) has a value of 1 at 0 distance, 0 at 2*cutoff, and decreases in an approximation of a gaussian in between.
Type 2 (Boxcar) is 1 from 0 to 2*cutoff, and then 0 beyond.
Type 3 (Ramped Boxcar) is 1 to cutoff and then ramps linearly down to 0 at 2*cutoff.
&location_nml :: horiz_dist_onlyvalid values: .true., .false.
If set to .true., then the vertical location of all items, observations and state vector both, are ignored when computing distances between pairs of locations. This has the effect that all items within a vertical-cylindrical area are considered the same distance away.
If set to .false., then the full 3d separation is computed. Since the localization is computed in radians, the 2d distance is easy to compute but a scaling factor must be given for the vertical since vertical coordinates can be in meters, pressure, or model levels. See below for the ‘vert_normalization_xxx’ namelist items.
&location_nml :: vert_normalization_{pressure,height,level,scale_height}valid values: real numbers, in pascals, meters, index, and value respectively
If ‘horiz_dist_only’ is set to .true., these are ignored. If set to .false., these are required. They are the amount of that quantity that is equivalent to 1 radian in the horizontal. If the model is an earth-based one, then one radian is roughly 6366 kilometers, so if vert_normalization_height is set to 6366000 meters, then the localization cutoff will be a perfect sphere. If you want to localize over a larger distance in the vertical than horizontal, use a larger value. If you want to localize more sharply in the vertical, use a smaller number. The type of localization used is set by which type of vertical coordinate the observations and state vector items have.
If you have observations with different vertical coordinates (e.g. pressure and height), or if your observations have a different vertical coordinate than your state vector items, or if you want to localize in a different type of unit than your normal vertical coordinate (e.g. your model uses pressure in the vertical but you wish to localize in meters), then you will need to modify or add a
get_close()routine in yourmodel_mod.f90file. See the discussion in the MODULE location_mod (threed_sphere) documentation for how to transform vertical coordinates before localization.&assim_tools_nml ::adaptive_localization_thresholdvalid values: integer counts, or -1 to disable
Used to dynamically shrink the localization cutoff in areas of dense observations. If set to something larger than 0, first the number of other observations within 2*cutoff is computed. If it is larger than this given threshold, the cutoff is decreased proportionally so if the observations were evenly distributed in space, the number of observations within 2*revised_cutoff would now be the threshold value. The cutoff value is computed for each observation as it is assimilated, so can be different for each one.
&assim_tools_nml :: adaptive_cutoff_floorvalid values: 0.0 to infinity, or -1 to disable
If using adaptive localization (adaptive_localization_threshold set to a value greater than 0), then this value can be used to set a minimum cutoff distance below which the adaptive code will not shrink. Set to -1 to disable. Ignored if not using adaptive localization.
&assim_tools_nml :: output_localization_diagnosticsvalid values: .true., .false.
If .true. and if adaptive localization is on, a single text line is printed to a file giving the original cutoff and number of observations, and the revised cutoff and new number of counts within this smaller cutoff for any observation which has nearby observations which exceed the adaptive threshold count.
&assim_tools_nml :: localization_diagnostics_filevalid values: text string
Name of the file where the adaptive localization diagnostic information is written.
&assim_tools_nml :: special_localization_obs_typesvalid values: list of 1 or more text strings
The cutoff localization setting is less critical in DART than it might be in other situations since during the assimilation DART computes the covariances between observations and nearby state vector locations and that is the major factor in controlling the impact an observation has. For conventional observations fine-tuning the cutoff based on observation type is not recommended (it is possible to do more harm than good with it). But in certain special cases there may be valid reasons to want to change the localization cutoff distances drastically for certain kinds of observations. This and the following namelist items allow this.
Optional list of observation types (e.g. “RADAR_REFLECTIVITY”, “AIRS_TEMPERATURE”) which will use a different cutoff distance. Any observation types not listed here will use the standard cutoff distance (set by the ‘cutoff’ namelist value). This is only implemented for the threed_sphere location module (the one used by most geophysical models.)
&assim_tools_nml :: special_localization_cutoffsvalid values: list of 1 or more real values, 0.0 to infinity
A list of real values, the same length as the list of observation types, to be used as the cutoff value for each of the given observation types. This is only implemented for the threed_sphere location module (the one used by most geophysical models.)
Guidance regarding localization
There are a large set of options for localization. Individual cases may differ but in general the following guidelines might help. Most users use the Gaspari-Cohn covariance cutoff type. The value of the cutoff itself is the item most often changed in a sensitivity run to pick a good general value, and then left as-is for subsequent runs. Most localize in the vertical, but tend to use large values so as to not disturb vertical structures. Users do not generally use adaptive localization, unless their observations are very dense in some areas and sparse in others.
The advice for setting good values for the cutoff value is to err on the larger side - to estimate for all types of observations under all conditions what the farthest feasible impact or correlated structure size would be. The downsides of guessing too large are 1) run time is slower, and 2) there can be spurious correlations between state vector items and observations which aren’t physically related and noise can creep into the assimilation results this way. The downside of guessing too small is that state vector items that should get an impact from an observation won’t. This might disrupt organized features in a field and the model may take more time to recover/reconstruct the feature.
Namelist
This namelist is read from the file input.nml. Namelists start with an ampersand ‘&’ and terminate with a slash ‘/’.
Character strings that contain a ‘/’ must be enclosed in quotes to prevent them from prematurely terminating the
namelist.
&assim_tools_nml
cutoff = 0.2
distribute_mean = .false.
sort_obs_inc = .true.
spread_restoration = .false.
sampling_error_correction = .false.
adaptive_localization_threshold = -1
adaptive_cutoff_floor = 0.0
output_localization_diagnostics = .false.
localization_diagnostics_file = "localization_diagnostics"
print_every_nth_obs = 0
rectangular_quadrature = .true.
gaussian_likelihood_tails = .false.
close_obs_caching = .true.
adjust_obs_impact = .false.
obs_impact_filename = ""
allow_any_impact_values = .false.
convert_all_obs_verticals_first = .true.
convert_all_state_verticals_first = .false.
special_localization_obs_types = 'null'
special_localization_cutoffs = -888888.0
/
Description of each namelist entry
cutofftype: real(r8)
Cutoff controls a distance dependent weight that modulates the impact of an observation on a state variable. The units depend both on the location module being used and on the covariance cutoff module options selected. As defined in the original paper, this is the half-width; the localization goes to 0 at 2 times this value.
distribute_meantype: logical
If your model uses coordinates that have no options for different vertical coordinates then this setting has no effect on speed and should be .true. to use less memory. If your model has code to convert between different coordinate systems, for example Pressure, Height, Model Levels, etc, then setting this .false. will generally run much faster at assimilation time but will require more memory per MPI task. If you run out of memory, setting this to .true. may allow you to run but take longer.
sort_obs_inctype: logical
If true, the final increments from obs_increment are sorted so that the mean increment value is as small as possible. Applies to ENKF only.
sort_obs_incminimizes regression errors when non-deterministic filters or error correction algorithms are applied. HOWEVER, when using deterministic filters with no inflation or a combination of a determinstic filter and deterministic inflation (filter_nml:inf_deterministic = .TRUE.) sorting the increments is both unnecessary and expensive.spread_restorationtype: logical
True turns on algorithm to restore amount of spread that would be expected to be lost if underlying obs/state variable correlation were really 0.
Warning
spread_restoration is not supported in this version, please reach out to the DAReS team dart@ucar.edu
if you need to use spread_restoration.
sampling_error_correctiontype: logical
If true, apply sampling error corrections to the correlation values based on the ensemble size. See Anderson 2012. This option uses special input files generated by the gen_sampling_err_table tool in the assimilation_code/programs directory. The values are generated for a specific ensemble size and most common ensemble sizes have precomputed entries in the table. There is no dependence on which model is being used, only on the number of ensemble members. The input file must exist in the directory where the filter program is executing.
adaptive_localization_thresholdtype: integer
Used to reduce the impact of observations in densely observed regions. If the number of observations close to a given observation is greater than the threshold number, the cutoff radius for localization is adjusted to try to make the number of observations close to the given observation be the threshold number. This should be dependent on the location module and is tuned for a three_dimensional spherical implementation for numerical weather prediction models at present.
adaptive_cutoff_floortype: real
If adaptive localization is enabled and if this value is greater than 0, then the adaptive cutoff distance will be set to a value no smaller than the distance specified here. This guarentees a minimum cutoff value even in regions of very dense observations.
output_localization_diagnosticstype: logical
Setting this to
.true.will output an additional text file that contains the obs key, the obs time, the obs location, the cutoff distance and the number of other obs which are within that radius. If adaptive localization is enabled, the output also contains the updated cutoff distance and the number of other obs within that new radius. Without adaptive localization there will be a text line for each observation, so this file could get very large. With adaptive localization enabled, there will only be one line per observation where the radius is changed, so the size of the file will depend on the number of changed cutoffs.localization_diagnostics_filetype: character(len=129)
Filename for the localization diagnostics information. This file will be opened in append mode, so new information will be written at the end of any existing data.
print_every_nth_obstype: integer
If set to a value
Ngreater than 0, the observation assimilation loop prints out a progress message everyNth observations. This can be useful to estimate the expected run time for a large observation file, or to verify progress is being made in cases with suspected problems.rectangular_quadraturetype: logical
Only relevant for filter type UNBOUNDED_RHF and recommended to leave
.true..gaussian_likelihood_tailstype: logical
Only relevant for filter type UNBOUNDED_RHF and recommended to leave
.false..close_obs_cachingtype: logical
Should remain .TRUE. unless you are using specialized_localization_cutoffs. In that case to get accurate results, set it to .FALSE.. This also needs to be .FALSE. if you have a get_close_obs() routine in your model_mod file that uses the types/kinds of the obs to adjust the distances.
adjust_obs_impacttype: logical
If true, reads a table of observation quantities and types which should be artifically adjusted regardless of the actual correlation computed during assimilation. Setting the impact value to 0 prevents items from being adjusted by that class of observations. The input file can be constructed by the ‘obs_impact_tool’ program, included in this release. See the documentation for more details.
obs_impact_filenametype: character(len=256)
If adjust_obs_impact is true, the name of the file with the observation types and quantities and state quantities that should have an additional factor applied to the correlations during assimilation.
allow_any_impact_valuestype: logical
If .false., then the impact values can only be zero or one (0.0 or 1.0) - any other value will throw an error. .false. is the recommended setting.
convert_all_obs_verticals_firsttype: logical
Should generally always be left .True.. For models without vertical conversion choices the setting of this item has no impact.
convert_all_state_verticals_firsttype: logical
If the model has multiple choices for the vertical coordinate system during localization (e.g. pressure, height, etc) then this should be .true. if previous versions of get_state_meta_data() did a vertical conversion or if most of the state is going to be impacted by at least one observation. If only part of the state is going to be updated or if get_state_meta_data() never used to do vertical conversions, leave it .false.. The results should be the same but the run time may be impacted by doing unneeded conversions up front. For models without vertical conversion choices the setting of this item has no impact.
special_localization_obs_typestype: character(len=32), dimension(:)
Optional list of observation types (e.g. “RADAR_REFLECTIVITY”, “RADIOSONDE_TEMPERATURE”) which will use a different cutoff value other than the default specified by the ‘cutoff’ namelist. This is only implemented for the ‘threed_sphere’ locations module.
special_localization_cutoffstype: real(r8), dimension(:)
Optional list of real values which must be the same length and in the same order as the observation types list given for the ‘special_localization_obs_types’ item. These values will set a different cutoff distance for localization based on the type of the observation currently being assimilated. Any observation type not in the list will use the default cutoff value. This is only implemented for the ‘threed_sphere’ locations module.
Other modules used
types_mod
utilities_mod
sort_mod
random_seq_mod
obs_sequence_mod
obs_def_mod
cov_cutoff_mod
reg_factor_mod
location_mod (model dependent choice)
ensemble_manager_mod
mpi_utilities_mod
adaptive_inflate_mod
time_manager_mod
assim_model_mod
Public interfaces
use assim_tools_mod, only : |
filter_assim |
A note about documentation style. Optional arguments are enclosed in brackets [like this].
call filter_assim(ens_handle, obs_ens_handle, obs_seq, keys, ens_size, num_groups, obs_val_index, inflate, ens_mean_copy, ens_sd_copy, ens_inf_copy, ens_inf_sd_copy, obs_key_copy, obs_global_qc_copy, obs_prior_mean_start, obs_prior_mean_end, obs_prior_var_start, obs_prior_var_end, inflate_only)
type(ensemble_type), intent(inout) :: ens_handle
type(ensemble_type), intent(inout) :: obs_ens_handle
type(obs_sequence_type), intent(in) :: obs_seq
integer, intent(in) :: keys(:)
integer, intent(in) :: ens_size
integer, intent(in) :: num_groups
integer, intent(in) :: obs_val_index
type(adaptive_inflate_type), intent(inout) :: inflate
integer, intent(in) :: ens_mean_copy
integer, intent(in) :: ens_sd_copy
integer, intent(in) :: ens_inf_copy
integer, intent(in) :: ens_inf_sd_copy
integer, intent(in) :: obs_key_copy
integer, intent(in) :: obs_global_qc_copy
integer, intent(in) :: obs_prior_mean_start
integer, intent(in) :: obs_prior_mean_end
integer, intent(in) :: obs_prior_var_start
integer, intent(in) :: obs_prior_var_end
logical, intent(in) :: inflate_only
Does assimilation and inflation for a set of observations that is identified by having integer indices listed in keys. Only the inflation is updated if inflation_only is true, otherwise the state is also updated.
|
Contains state variable ensemble data and description. |
|
Contains observation prior variable ensemble and description. |
|
Contains the observation sequence including observed values and error variances. |
|
A list of integer indices of observations in obs_seq that are to be used at this time. |
|
Number of ensemble members in state and observation prior ensembles. |
|
Number of groups being used in assimilation. |
|
Integer index of copy in obs_seq that contains the observed value from instrument. |
|
Contains inflation values and all information about inflation to be used. |
|
Index of copy containing ensemble mean in ens_handle. |
|
Index of copy containing ensemble standard deviation in ens_handle. |
|
Index of copy containing state space inflation in ens_handle. |
|
Index of copy containing state space inflation standard deviation in ens_handle. |
|
Index of copy containing unique key for observation in obs_ens_handle. |
|
Index of copy containing global quality control value in obs_ens_handle. |
|
Index of copy containing first group’s prior mean in obs_ens_handle. |
|
Index of copy containing last group’s prior mean in obs_ens_handle. |
|
Index of copy containing first group’s ensemble variance in obs_ens_handle. |
|
Index of copy containing last group’s ensemble variance in obs_ens_handle. |
|
True if only inflation is to be updated, and not state. |
Files
filename |
purpose |
|---|---|
input.nml |
to read |
References
Anderson, J. L., 2001: An Ensemble Adjustment Kalman Filter for Data Assimilation. Mon. Wea. Rev., 129, 2884-2903. doi: 10.1175/1520-0493(2001)129<2884:AEAKFF>2.0.CO;2
Anderson, J. L., 2003: A Local Least Squares Framework for Ensemble Filtering. Mon. Wea. Rev., 131, 634-642. doi: 10.1175/1520-0493(2003)131<0634:ALLSFF>2.0.CO;2
Anderson, J., Collins, N., 2007: Scalable Implementations of Ensemble Filter Algorithms for Data Assimilation. Journal of Atmospheric and Oceanic Technology, 24, 1452-1463. doi: 10.1175/JTECH2049.1
Anderson, J. L., 2010: A Non-Gaussian Ensemble Filter Update for Data Assimilation. Mon. Wea. Rev., 139, 4186-4198. doi: 10.1175/2010MWR3253.1
Anderson, J. L., 2012:, Localization and Sampling Error Correction in Ensemble Kalman Filter Data Assimilation. Mon. Wea. Rev., 140, 2359-2371. doi: 10.1175/MWR-D-11-00013.1
Poterjoy, J., 2016:, A localized particle filter for high-dimensional nonlinear systems. Mon. Wea. Rev. 144 59-76. doi:10.1175/MWR-D-15-0163.1
Private components
N/A